Hadoop系统提供了MapReduce计算框架的开源实现,像Yahoo!、Facebook、淘宝、中移动、百度、腾讯等公司都在借助Hadoop进行海量数据处理。Hadoop系统性能不仅取决于任务调度器的分配策略,还受到分配后实际任务执行效率的影响,任务执行常常涉及读取、排序、归并、压缩、写入等具体阶段。
HCE计算框架是一个开源项目,旨在通过优化任务执行的各个阶段,提升整个Hadoop系统的效率。与Hadoop Java框架相比,基于HCE框架的MapReduce任务最高可以节省超过30%的CPU资源使用。
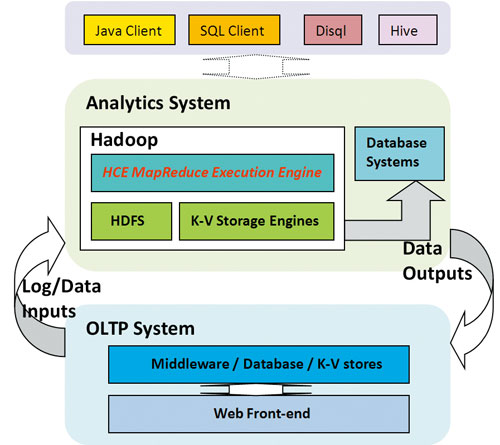
图1 Hadoop生态系统中的HCE计算框架
图1给出了HCE框架在Hadoop生态系统中所处的位置。对于OLTP系统来说,用户通过Web前端生成相应请求,请求经过中间件处理,作为数据进入数据库或者K-V存储系统中,同时会产生日志。OLTP系统产生的数据和日志都会作为分析系统的输入,对于搜索引擎和广告系统来说,每天的日志会轻松超过TB。日志和业务数据一般会存放到海量存储系统HDFS文件系统或者K-V存储系统中,分布式计算框架MapReduce一般会基于存储系统之上。每天会执行成千上万的MapReduce作业进行海量数据处理,产生的结果会有三个去处:存放于海量存储系统以备后续使用;导入用于产生报表或分析的数据库;作为OLTP系统的输入,导入线上存储中。MapReduce作业一般由内部用户通过Hadoop原生客户端、Pig/DISQL语言客户端或者Hive数据仓库三种方式进行提交,作业执行结果可以通过SQL客户端查询。
#问题
越来越多的公司开始使用Hadoop及其周边系统进行海量数据分析,Yahoo!和Facebook的Hadoop集群节点数已经过万,并且节点增长的趋势不减,国内公司如腾讯和百度等也面临着同样的问题。不断增长的业务需求和业务数据导致的集群资源紧缺是集群不断扩容的主要原因,CPU资源(注:存储资源紧缺的解决方案之一是开启重量级的压缩(如Facebook),这涉及CPU资源的使用)又是其中最为紧缺的。为了控制成本,优化集群资源利用率势在必行。
对于分布式计算层面,资源优化有两个途径:一是通过精细化的资源调度来保证全局资源的最大化利用,这通常涉及合理的资源调度算法和轻量级的资源隔离;二是通过优化计算任务和用户程序来提升原有计算作业的资源使用率。HCE计算框架主要关注后者。
##跨平台、高扩展、通用接口的计算框架也带来了额外开销
分析Hadoop MapReduce计算框架,已有实现可以再做权衡。
MapReduce框架通过Java语言高效实现,保证了其跨平台的兼容性;不过国内互联网公司一般都使用Intel x86平台,兼容性的优势很难得以体现,因此可以选择优于Java性能但不支持跨平台的语言来实现MapReduce框架。
为了最大化可扩展性(Extensibility),Hadoop实现了多层级的数据处理流封装,这使得Java框架在大数据处理时存在一些性能损耗,实际上可以实现更加直接的数据处理路径来提升处理效率。
国内互联网公司的工程师们大多使用C++进行功能开发或脚本语言来处理文本,Java接口对于他们而言是比较麻烦的事情。Hadoop提供了Streaming编程接口,允许用户程序可以通过媒介——标准输入输出来和计算框架交互数据,也即绕开了语言的限制,因此很多用户任务是通过Streaming接口启动的。Streaming接口的优势在于支持多语言开发,而增加通用性带来的是性能的损耗,即数据拷贝管道和Key切分开销(大约2%~5%),并且不如原生态的语言接口更加适宜编程。
##用户程序在计算框架控制之外
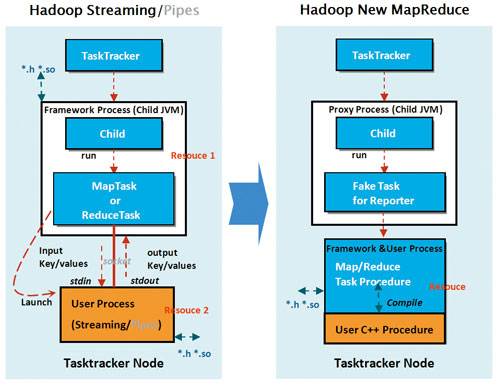
图2 MapReduce任务执行框架示意图
除了框架的开销,计算任务的资源占用还包括用户程序。如图2所示,Hadoop Streaming和Pipes框架支持C++用户开发MapReduce应用程序,框架启动用户可执行程序,框架和用户程序分别处于两个进程,分别占用资源。简单的分析程序不会占用太多的CPU资源,即用户程序在整个计算任务执行时间中所占比例不大,此时,优化计算框架会带来比较可观的收益;不过,对于复杂的分析程序而言,用户程序所占时间远远超过计算框架,此时,优化计算框架带来的收益可能微乎其微。因此,节省集群CPU资源离不开优化用户程序。
优化用户作业可以分为两个层面,一是通过较高层次的统一入口让用户提交作业,例如使用数据仓库Hive的用户不会操作Hadoop MapReduce的API,在Hive内部统一做优化,包括一些静态或者动态方法,调整用户作业参数,使任务利用最少资源高效执行;二是优化直接操作MapReduce API的用户作业,当然Hive也属于这个范畴。设想用户作业或者数据仓库是通过C++语言实现的,编译由用户实施,平台仅仅通过接口调用用户的可执行程序,那么此时想要优化用户程序会比较困难。有动态和静态两种优化方式:动态优化方式(注:详情参见Starfish: A Selftuning System for Big Data Analytics (CIDR’11))是在MapReduce上新增一层,通过profiler和sampler等技术动态调整作业参数;静态优化方式是让用户用编译时依赖框架提供的头文件和库文件,通过编译优化技术提升用户程序性能。
#解决
HCE计算框架通过静态优化计算框架和用户程序来提升计算任务的CPU使用率。如图2所示,将框架和用户程序整合到一个进程,可以通过同一套编译机制同时优化框架和用户程序,Key-Values处理也处于同一个进程空间,不用借助媒介(管道或套接字)来传递。HCE和Hadoop提供的用户编程接口如表1所示。
表1 MapReduce框架各用户接口对比
##计算框架高效C++实现
HCE框架通过C++语言实现了MapReduce的数据处理逻辑,依托比Java性能更优的C++语言,可以在数据处理操作上获得更佳的CPU利用率,同时也可以更加直接地调用Native Lib而非通过JNI(注:压缩库是Native实现,Hadoop通过JNI来调用压缩方法,HCE压缩在一个进程空间执行);此外,通过高效的编译优化方法,例如ICC编译器等,可以进一步挖掘框架的性能优势。
HCE框架通过精简的方式实现了MapReduce的数据处理流程,比较多层次的Java流式封装,HCE的处理流程更加高效。
HCE框架提供了多种语言接口C++、Python等,方便了用户编程,也节省了Streaming接口的额外开销;同时HCE也提供完全兼容原有Java Streaming的接口,即原有作业可以无缝迁移到HCE框架。
##用户程序静态编译优化
HCE框架采用的是静态优化用户程序的方式,动态优化交给上层的数据仓库去做。对于那些CPU负载较重的用户程序,HCE提供C++编程接口给用户,用户编译本地程序需要依赖框架的头文件和库文件,头文件中内置了如SSE等优化代码,可以使得用户程序在编译时被优化。这种简单的方式能够使得用户程序的执行效率大幅提升。
#框架
HCE框架实现了Hadoop支持的功能组件,例如在C++空间中支持Text或者SequenceFile格式的RecordReader和RecordWriter,也支持Gzip、Lzo、QuickLz、Lzma等4种压缩格式。由于输入文件切分是在Hadoop Client实施的,所以Split方法还是在Java空间执行的;当然,用户定义的Mapper和Reducer必须在C++空间实现,例如Hive想要基于HCE框架执行,那么就必须实现C++版本的Mapper、Reducer等功能组件。
图3 HCE框架数据处理流程图
图3展示了HCE框架的数据处理流程,可以看出HCE框架在C++空间高效实现了多个可扩展的功能模块,如RecordReader、OutputCollector、Shuffle、ReduceInputReader、RecordWriter、Committer、Partitioner、Mapper、Reducer、Combiner等,处理逻辑比Hadoop MapReduce更加紧凑高效。处于Hadoop Java空间的MapRunner和ReduceRunner只是起到收集状态信息的作用。
HCE框架的性能提升主要集中在Map阶段,大约超过40%。对于一般的MapReduce程序,相比Shuffle和Reduce阶段,Map阶段也是其资源占用最多的阶段,因为最终作业的输出一般仅仅是输入的10%,大量的数据处理是在Map阶段完成的。
#拓展
仅有基本的HCE框架是不够的,因为大量已有作业是通过Streaming接口执行的,而且除C++开发接口之外,脚本开发者也想使用对应语言的开发接口。幸运的是,所有脚本语言都基于C开发,因此可以实现简单的解释器,将脚本语言翻译成C语言,最终执行的仍是HCE框架,而这个解释开销很小。当然,Streaming作业的额外开销是不可避免了,不过基于HCE框架的Streaming作业可以利用框架的性能优势获得CPU利用率的提升,这对于轻量级作业收益仍然可观。
图4展示了Java Streaming、HCE、Streaming Over HCE和Python Over HCE四个框架的数据处理途径。Java Streaming框架的数据处理仍然是在Java空间完成的,而HCE、Streaming Over HCE、Python Over HCE框架的数据处理都在C++空间完成,Child JVM仅从HCE进程收集任务状态信息。
图4 Streaming Over HCE和Python Over HCE框架示意图
#未来
MapReduce计算框架并不仅仅依赖于HDFS存储系统,也可以基于其他存储系统,例如Hypertable或者是其他的K-V系统。目前很多块存储系统或K-V系统都是C++语言实现的,想要在其上使用原生态的Hadoop MapReduce,就必须通过存储系统的语言转换接口(例如Hypertable的Thrift)或者计算系统的转换接口(例如Hadoop的AvroRPC等),问题是数据的序列化和反序列化难免带来额外开销。因此,基于HCE框架、非Java语言实现的存储系统可以更加高效地支持Hadoop MapReduce计算,当然它们需要实现对应的Split、RecordReader、RecordWriter和Committer等组件。
#小结
HCE框架是Hadoop MapReduce框架的一个衍生品。依托HCE框架的高效本地处理机制,Hadoop作业可以最多节省30%的CPU资源使用。此外,HCE提供了C++、Python等多种编程接口,并且保证了已有接口的向前兼容;多种编译优化技术也可以方便地应用到MapReduce框架;最后,HCE通过编译优化和内置解释器等方式优化了用户程序的执行。